The Detectability Limitation of Community
博士的研究课题是关于网络节点属性可预测性的极限:即在知道了网络的结构后,网络节点属性预测的准确率理论上限能有多高。一个类似的问题是网络社团检测的可检测性,当网络满足某些条件时,网络社团在理论上就是不可检测的。存在一个detectability-undetectability的相变。而且还存在一个easy-hard的相变,即是否存在多项式时间的算法解决社团检测问题。2011年的这篇论文:Asymptotic analysis of the stochastic block model for modular networks and its algorithmic applications.比较系统的分析了这一问题,该文涉及到的一些概念Belief Propagation, Bethe free energy, Phase transition比较难以理解。在此做一笔记,作本人对该问题的个人注解,思路梳理。
SBM Definition & Question
\(q\) - the number of the groups.
\(n_a\) - the expected fraction of node in group \(a\).
\(N\) - the number of nodes.
\(p_{ab}\) - \(q\times q\) affinity matrix, the probability of an edge between group \(a\) and group \(b\).
\(q_i\) - the group label of node i.
\(N_a = N\times n_a\) - the number of nodes in group \(a\).
\(c_{ab} = N\times p_{ab}\) - the rescaled affinity matrix.
\(M_{ab}=p_{ab}N_aN_b\) - the average number of edges between group a and b.
\(M_{aa}=p_{aa}N_a(N_a-1)\) - the average number of edges in group a.
\(M\) - the number of edges.
Average degree \(c\) for \(N\to \infty\)
-
有向图。 对有向图而言,平均度是网络的平均出度。一条边贡献一个出度,所以\(有向图的平均度=\frac{网络的边数}{网络的节点数}\)。即
\[\begin{aligned}c&=lim_{N\to \infty}\frac{\sum_{a \neq b}p_{ab}Nn_aNn_b+\sum_{a==b}p_{aa}Nn_a(Nn_a-1)}{N}\\&=\sum_{a \neq b}c_{ab}n_an_b+\sum_{a==b}c_{aa}n_an_a\\&=\sum_{a,b}c_{ab}n_an_b\end{aligned}\] -
无向图。
\[无向图的平均度=\frac{2*网络的边数}{网络的节点数}\] \[\begin{aligned}c&=lim_{N\to\infty}\frac{2\sum_{a<b}p_{ab}Nn_aNn_b+2\sum_{a==b}p_{aa}Nn_a(Nn_a-1)/2}{N}\\&=2\sum_{a<b}c_{ab}n_an_b+\sum_{a}c_{aa}n_a^2\end{aligned}\]这个结果是论文的结果公式(2)的2倍
TODO,但或许对后面的核心内容没有太大影响。
Question
- 已知图G,SBM的参数 \(\begin{aligned}\theta=\left\lbrace q,\left\lbrace n_a\right\rbrace ,\left\lbrace p_{ab}\right\rbrace \right\rbrace \end{aligned}\) 最可能的值是什么: parameter learning
- 已知图G和参数\(\theta\),节点的组标签\(q_i\)的最可能的值是什么: inferring the group assignment
对于第2个问题,我们这里可以先考虑一个简单的问题:如何量化标签\(\left\lbrace q_i\right\rbrace\)的好坏,设真实的标签为\(\left\lbrace t_i\right\rbrace\)。一个直接的想法是考虑\(\left\lbrace q_i\right\rbrace\)和\(\left\lbrace t_i\right\rbrace\)一致的个数,由于我们估计的标签\(\left\lbrace q_i\right\rbrace\)有着不同的排列,这会影响对一致个数的计算,所以我们可以取所有排列中,结果最好的一个,记作\(agreement:A(\left\lbrace t_i\right\rbrace ,\left\lbrace q_i\right\rbrace )=max_\pi\frac{\sum_i\delta_{t_i, \pi(q_i)}}{N}\),其中\(\pi\)是节点标签不同的排列方式。
一种简单的估计节点标签的方式是,把所有的标签设为最大的组的标签。以这样的方法为基准,我们可以定义normalized agreement, 叫做overlap
\[overlap:Q(\left\lbrace t_i\right\rbrace ,\left\lbrace q_i\right\rbrace )=max_\pi\frac{\frac{1}{N}\sum_i\delta_{t_i, \pi(q_i)}-max_an_a}{1-max_an_a}\]overlap范围0~1,越高越好,当估计标签完全拟合真实标签时,overlap为1。
Bayesian Inference & Statistical Physics
Bayesian for inferring the group assignment
假设我们已经解决了parameter learning,得到了\(\theta\)。给定SBM的参数\(\theta\)后,生成图\(G\)(邻接矩阵为\(A\)),以及节点标签\({q_i}\)的概率为
\[\begin{aligned}P(\left\lbrace q_i\right\rbrace ,G|\theta)=\prod_{i\neq j}[p_{q_iq_j}^{A_{ij}}(1-p_{q_iq_j})^{1-A_{ij}}]\prod_in_{q_i}\end{aligned}\tag{2.1.1}\]实际情况下,我们是知道网络的图\(G\)的。我们想要知道 \(P(\left\lbrace q_i\right\rbrace \vert G, \theta)\), 根据贝叶斯公式:
\[\begin{aligned}P(\left\lbrace q_i\right\rbrace |G, \theta)&=\frac{P(\left\lbrace q_i\right\rbrace ,G,\theta)}{\sum_{t_i}P(\left\lbrace t_i\right\rbrace ,G,\theta)}\\&=\frac{P(\left\lbrace q_i\right\rbrace ,G|\theta)P(\theta)}{\sum_{t_i}P(\left\lbrace t_i\right\rbrace ,G|\theta)P(\theta)}\\P(\left\lbrace q_i\right\rbrace |G, \theta)&=\frac{P(\left\lbrace q_i\right\rbrace ,G|\theta)}{\sum_{t_i}P(\left\lbrace t_i\right\rbrace ,G|\theta)}\end{aligned}\tag{2.1.2}\]这样将(2.1.1)代入(2.1.2)就可以得到 \(P(\left\lbrace q_i\right\rbrace \vert G, \theta)\) 的显式公式。这里解决了一个之前一直比较疑惑的点,当遇到条件概率和联合概率组合起来时就会让人很困惑。例如\(P(A\|B,C)\)应该理解为A在给定B,C下的条件概率呢,还是A给定B的条件概率,和C的联合概率。其实应该是前者理解是正确的,而且
\[\begin{aligned}P(A|B,C)&=\frac{P(A,B|C)P(C)}{P(B|C)P(C)}=\frac{P(A,B|C)}{P(B|C)}\\&=\frac{P(A,C|B)P(B)}{P(C|B)P(B)}=\frac{P(A,C|B)}{P(C|B)}\end{aligned}\]这样写就看上去好像是后一种理解,但其实应该是前一种理解推出来的。
Boltzmann distribution
公式(2.1.2)的右半部分类似于统计物理中的玻尔兹曼分布。假设一个系统由N个粒子构成,每个粒子\(i\)的状态记作\(x_i\)。整个系统的状态 \(\left\lbrace x\right\rbrace\) 对应的能量为\(E(\left\lbrace x\right\rbrace )\)。则系统状态的玻尔兹曼分布为:
\[p(\left\lbrace x\right\rbrace )=\frac{e^{-\beta E(\left\lbrace x\right\rbrace )}}{Z(\beta)}, where\ Z(\beta)=\sum_{\left\lbrace x^`\right\rbrace \in S}e^{-\beta E(\left\lbrace x^`\right\rbrace )}\tag{2.2.1}\]稳定条件下系统的概率分布与系统能量的关系为(这里\(H(\left\lbrace x\right\rbrace )\)类似于上式中的\(E(\left\lbrace x\right\rbrace )\) ):
\[P(\left\lbrace x\right\rbrace )\propto e^{-\beta H(\left\lbrace x\right\rbrace )}\]我们设\(\beta=1\),(2.1.2)中的\(\left\lbrace q_i\right\rbrace\)即为系统的状态,则系统在状态\(\left\lbrace q_i\right\rbrace\)下的能量\(H(\left\lbrace q_i\right\rbrace )\)(也即Hamiltonian)为
\[\begin{aligned}H(\left\lbrace q_i\right\rbrace )&=-logP(\left\lbrace q_i\right\rbrace , G|\theta)\\&=-\sum_{i\neq j}[A_{ij}log\ p_{q_iq_j}+(1-A_{ij})log(1-p_{q_iq_j})]-\sum_ilog\ n_{q_i}\\&=-\sum_{i\neq j}[A_{ij}log\ \frac{c_{q_iq_j}}{N}+(1-A_{ij})log(1-\frac{c_{q_iq_j}}{N})]-\sum_ilog\ n_{q_i}\\&=-\sum_{i\neq j}[A_{ij}log\ c_{q_iq_j}+(1-A_{ij})log(1-\frac{c_{q_iq_j}}{N})]-\sum_ilog\ n_{q_i}+\sum_{i\neq j}A_{ij}logN\\H(\left\lbrace q_i\right\rbrace )&=-\sum_{i\neq j}[A_{ij}log\ c_{q_iq_j}+(1-A_{ij})log(1-\frac{c_{q_iq_j}}{N})]-\sum_ilog\ n_{q_i}\ (ignore\ MlogN)\end{aligned}\tag{2.2.2}\]这里忽略掉最后一项,我以为是忽略掉结果中与\(\left\lbrace q_i\right\rbrace\)无关的一项,论文中的解释是想让这个能量extensive,保持一些属性与N成比例TODO。
这样,这个系统的玻尔兹曼分布以及配分函数(partition function)即为:
\[\begin{aligned}\mu(\left\lbrace q_i\right\rbrace |G,\theta)&=\frac{e^{-H(\left\lbrace q_i\right\rbrace )}}{\sum_{\left\lbrace q_i\right\rbrace }e^{-H(\left\lbrace q_i\right\rbrace )}}\end{aligned}\tag{2.2.3}\] \[Z(G,\theta)=\sum_{\left\lbrace q_i\right\rbrace }e^{-H(\left\lbrace q_i\right\rbrace )}\tag{2.2.4}\]Bayesian for parameter learning
之前假设我们已知了\(\theta= \left \lbrace q, \left\lbrace n_a\right\rbrace , \left\lbrace p_{ab}\right\rbrace \right \rbrace\), 但其实正常情况下我们只知道网络\(G\),所以我们需要解决\(P(\theta\|G)\)。根据贝叶斯公式:
\[P(\theta|G)=\frac{P(\theta)}{P(G)}P(G|\theta)=\frac{P(\theta)}{P(G)}\sum_{\left\lbrace q_i\right\rbrace }P(\left\lbrace q_i\right\rbrace ,G|\theta)\]\(p(\theta)\)是先验概率(prior),\(P(\theta\|G)\)是后验概率(posterior)。对于参数\(\theta\)的分布我们不做任何假设,简单视为uniform。所以最大化后验概率即为最大化\(\sum_{\left\lbrace q_i\right\rbrace }P(\left\lbrace q_i\right\rbrace ,G\vert \theta)\)。根据公式(2.2.2)和(2.2.4),这就是最大化配分函数\(Z(G,\theta)\)。而且等价于最小化free energy density:
\[f(G,\theta)=lim_{N\to \infty}\frac{F_N(G,\theta)}{N}=lim_{N\to \infty}\frac{-logZ(G,\theta)}{N}\]但什么是free energy?什么是free energy density?
Free Energy
Thermodynamic potentials
free energy \(F(\beta)\)是一个重要的热力学势能。考虑公式(2.2.1)表示的一个系统(这里加了一些符号表示):
\[p(\left\lbrace x\right\rbrace )=\mu_\beta(\left\lbrace x\right\rbrace )=\frac{e^{-\beta E(\left\lbrace x\right\rbrace )}}{Z(\beta)}, where\ Z(\beta)=\sum_{\left\lbrace x^`\right\rbrace \in S}e^{-\beta E(\left\lbrace x^`\right\rbrace )}\]\(Z(\beta)\)为配分函数,\(\beta\)为系统温度\(T\)的的倒数\(\beta=\frac{1}{T}\)。free energy即为配分函数\(Z(\beta)\)的对数乘以负温度。
\[F(\beta)=-\frac{1}{\beta}logZ(\beta)\tag{2.4.1}\]另两个重要的势能是internal energy \(U(\beta)\)和canonical entropy \(S(\beta)\)。
\[\begin{aligned}U(\beta)=\frac{\partial(\beta F(\beta))}{\partial \beta}\\S(\beta)=\beta^2\frac{\partial F(\beta)}{\partial \beta}\end{aligned}\tag{2.4.2}\]进一步推导\(F(\beta)\),\(U(\beta)\),\(S(\beta)\)的关系:
\[\begin{aligned}U(\beta)&=-\frac{\partial log(Z(\beta))}{\partial \beta}=-\frac{Z'(\beta)}{Z(\beta)}\\S(\beta)&=\beta^2\frac{\partial F(\beta)}{\partial \beta}=-\beta^2\frac{\frac{Z'(\beta)}{Z(\beta)}\beta-logZ(\beta)}{\beta^2}=logZ(\beta)-\beta\frac{Z'(\beta)}{Z(\beta)}\\F(\beta)&=U(\beta)-\frac{1}{\beta}S(\beta)\end{aligned}\tag{2.4.3}\]将\(Z(\beta)=\sum_{\left\lbrace x^`\right\rbrace \in S}e^{-\beta E(\left\lbrace x^`\right\rbrace )}\)代入\(U(\beta)\),\(S(\beta)\)中:
\[\begin{aligned}U(\beta)&=\frac{\sum_{\left\lbrace x^`\right\rbrace \in S}E(\left\lbrace x^`\right\rbrace )e^{-\beta E(\left\lbrace x^`\right\rbrace )}}{Z(\beta)}\\&=\sum_{\left\lbrace x^`\right\rbrace \in S}\frac{e^{-\beta E(\left\lbrace x^`\right\rbrace )}}{Z(\beta)}E(\left\lbrace x^`\right\rbrace )\\&=\left \langle E(\left\lbrace x^`\right\rbrace ) \right \rangle\end{aligned}\tag{2.4.4}\] \[\begin{aligned}S(\beta)&=\beta U(\beta)-\beta F(\beta)\\&=\sum_{\left\lbrace x^`\right\rbrace \in S}\mu_\beta({x^`})\beta E(\left\lbrace x^`\right\rbrace )+log\sum_{\left\lbrace x\right\rbrace \in S}e^{-\beta E(\left\lbrace x\right\rbrace )}\\&=\sum_{\left\lbrace x^`\right\rbrace \in S}\mu_\beta({x^`})\beta E(\left\lbrace x^`\right\rbrace )+\sum_{\left\lbrace x^`\right\rbrace \in S}\mu_\beta({x^`})log\sum_{\left\lbrace x\right\rbrace \in S}e^{-\beta E(\left\lbrace x\right\rbrace )}\\&=\sum_{\left\lbrace x^`\right\rbrace \in S}\mu_\beta({x^`})(\beta E(\left\lbrace x^`\right\rbrace )+log\sum_{\left\lbrace x\right\rbrace \in S}e^{-\beta E(\left\lbrace x\right\rbrace )})\\&=\sum_{\left\lbrace x^`\right\rbrace \in S}\mu_\beta({x^`})(-log\ e^{-\beta E(\left\lbrace x^`\right\rbrace )}+log\sum_{\left\lbrace x\right\rbrace \in S}e^{-\beta E(\left\lbrace x\right\rbrace )})\\&=-\sum_{\left\lbrace x^`\right\rbrace \in S}\mu_\beta({x^`})log\ \mu_\beta({x^`})\end{aligned}\tag{2.4.5}\]可以看出\(U(\beta)\)即为系统能量在玻尔兹曼分布下的平均值。\(S(\beta)\)就是玻尔兹曼分布的信息熵。
Thermodynamic limit
系统的自由能与系统的大小\(N\)有关,free energy density是在\(N\to\infty\)时,每一个粒子所占的自由能的平均值的极限: \(f(\beta)=lim_{N\to \infty}\frac{F_N(\beta)}{N}\) 类似的可以定义energy density \(u(\beta)\)和 entropy density \(s(\beta)\)。
Ising Model
TODO
Parameter learning
Sec. IIC. TODO
Cavity Method & Belief Propagation
根据公式(2.2.3):
\[\begin{aligned}\mu(\left\lbrace q_i\right\rbrace |G,\theta)&=\frac{e^{-H(\left\lbrace q_i\right\rbrace )}}{\sum_{\left\lbrace q_i\right\rbrace }e^{-H(\left\lbrace q_i\right\rbrace )}}\end{aligned}\]我们知道了所有节点标签分布的联合概率分布 \(\mu(\left\lbrace q_i\right\rbrace )\) 。但若想知道某一个节点标签的分布,即节点标签的边际分布(Marginal Distribution),我们即需要知道:
\[v_i(q_i)=\sum_{\left\lbrace q_j\right\rbrace _{j\neq i}}\mu(\left\lbrace q_j\right\rbrace _{j\neq i},q_i)\]Cavity Method 是统计物理中的一种方法:在Ising模型中,每一个粒子的状态依赖于其邻居的状态,如果我们初始化估计每个粒子的状态分布,然后根据邻居节点的状态分布迭代更新本节点的分布,最终收敛到一个分布即为最终的边际分布结果。这个方法类似于Belief Propagation(BP)方法,我们可以利用BP方法估计\(v_i(q_i)\)。
Belief Propagation
BP算法迭代的计算网络中节点的边际概率\(\psi_r^i\),其表示节点\(i\)的组标签为\(r\)的概率。可以想见,\(\psi_r^i\)是\(\overrightarrow{\psi^i}\)这个\(q\)维向量的一项:
\[\psi^i=\begin{bmatrix} \psi_1^i& \psi_2^i & ... &\psi_q^i \end{bmatrix}\tag{3.1.1}\]Naive Bayes
一个直观的想法是,节点邻居的边际分布会影响节点自身的边际分布,例如,节点\(i\)的邻居\(j\)属于组\(s\),而组\(r\)与组\(s\)的连边概率为\(p_{rs}\)。那么这条边\((i,j)\)对节点\(i\)的边际概率\(\psi_r^i\)的影响因数就是\(p_{rs}\)。假设节点\(i\)的不同邻居之间相互独立,考虑到节点\(i\)的不同邻居,以及每一个邻居属于不同组的边际概率\(\psi_s^j\),节点\(i\)的边际概率与其邻居的边际概率之间的关系为:
\[\psi_r^i\propto\prod_{j:(i,j)\in E}\sum_{s=1}^q\psi_s^jp_{rs}\]然后不断迭代这个式子,以至收敛,得到每个节点的边际分布。然而这样的想法太过简化,尤其是邻居之间相互独立的假设。BP算法修改了这个假设,节点的边际分布不互相独立,而是仅通过共同的邻居互相关联。
Belief Propagation
BP算法定义每个节点\(i\)发送给其邻居\(j\)的信息为\(\psi^{i\to j}\)。类似公式(3.1.1),这也是一个\(q\)维向量,\(\psi_r^{i\to j}\)含义为\(i\)假设没有\(j\)这个邻居,从其他邻居处估计的自身的组标签为\(r\)的边际概率,所以这个符号\(\psi_r^{i\to j}\)的含义核心在于\(i\)的边际分布,\(^{\to j}\)只是一个限定条件: \(i\)未知\(j\)这个邻居。
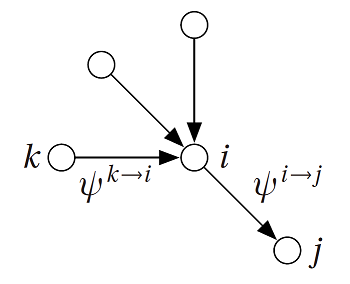
这样定义之后,如上图所示,\(\psi^{i\to j}\)即为\(i\)根据除了\(j\)之外的邻居\(k\),对自身边际分布的估计,借鉴Naive Bayes的思想,可以得知:
\[\psi_r^{i\to j}\propto\prod_{\begin{aligned}k:(&i,k)\in E\\&k\neq j\end{aligned}}\sum_{s=1}^q\psi_s^{k\to i}p_{rs}\tag{3.1.2}\]注意,在无向图中,每一条边有两个信息。
BP算法首先初始化每一条边上的信息,然后根据(3.1.2)式迭代直至收敛,最后根据边上的信息计算每一个节点的边际分布:
\[\psi_r^i\propto\prod_{j:(i,j)\in E}\sum_{s=1}^q\psi_s^{j\to i}p_{rs}\tag{3.1.3}\](3.1.2)中\(\psi_r^{i\to j}\)与\(\psi_s^{j\to i}\)无关,这阻止了信息回传到自身。BP算法在树状图中一定会收敛,但在一般的图中不一定收敛。但是当图很稀疏时,图中会出现局部树状的现象,这样BP算法会得到边际概率的一个很好的近似。此时,虽然节点自身的边际分布信息会经过一个大圈回到自身,但由于圈子过大,自身信息会被稀释,导致对结果影响不大。
BP in SBM
假设目前已知图G,以及生成图G的SBM的参数\(\theta=\left \lbrace q, \left\lbrace n_a\right\rbrace , \left\lbrace p_{ab}\right\rbrace \right \rbrace\)。使用BP算法inferring the group assignment。假设节点\(i\)可以接受每一个节点的信息,那么节点\(i\)的边际分布为:
\[\begin{aligned}\psi_{t_i}^{i\to j}&=\frac{1}{Z^{i\to j}}\prod_{k\in \partial i\setminus j}\sum_{t_k}p_{t_it_k}^{A_{ik}}(1-p_{t_it_k})^{1-A_{ik}}\psi_{t_k}^{k\to i}\\&=\frac{1}{Z^{i\to j}}\prod_{k\in \partial i\setminus j}\sum_{t_k}\frac{c_{t_it_k}}{N}^{A_{ik}}(1-\frac{c_{t_it_k}}{N})^{1-A_{ik}}\psi_{t_k}^{k\to i}\\&=\frac{1}{Z^{i\to j}}\prod_{k\in \partial i\setminus j}\frac{1}{N^{A_{ik}}}\sum_{t_k}c_{t_it_k}^{A_{ik}}(1-\frac{c_{t_it_k}}{N})^{1-A_{ik}}\psi_{t_k}^{k\to i}\\&=\frac{1}{Z^{i\to j}}\frac{1}{N^{d_i-1}}\prod_{k\in \partial i\setminus j}\sum_{t_k}c_{t_it_k}^{A_{ik}}(1-\frac{c_{t_it_k}}{N})^{1-A_{ik}}\psi_{t_k}^{k\to i},\ d_i:the\ degree\ of\ i\end{aligned}\]此处\(\partial i\)指代所有能传递给\(i\)信息的邻居。由于归一化的操作,可以忽略掉连乘项中不含\(t_i\)的项,即忽略掉\(\frac{1}{N^{d_i-1}}\)。得到:
\[\psi_{t_i}^{i\to j}=\frac{1}{Z^{i\to j}}\prod_{k\in \partial i\setminus j}\sum_{t_k}c_{t_it_k}^{A_{ik}}(1-\frac{c_{t_it_k}}{N})^{1-A_{ik}}\psi_{t_k}^{k\to i}\]然而论文中的公式却是:
\[\psi_{t_i}^{i\to j}=\frac{1}{Z^{i\to j}}n_{t_i}\prod_{k\in \partial i\setminus j}\sum_{t_k}c_{t_it_k}^{A_{ik}}(1-\frac{c_{t_it_k}}{N})^{1-A_{ik}}\psi_{t_k}^{k\to i}\tag{3.1.4}\]多了一项\(n_{t_i}\),这里表示的应该是先验概率,prior*likelyhood=posterior,我们以论文中的公式往下捋。
由公式(3.1.4),可以得知边际概率为:
\[v_i(t_i)=\psi_{t_i}^i=\frac{1}{Z^{i}}n_{t_i}\prod_{k\in \partial i}\sum_{t_k}c_{t_it_k}^{A_{ik}}(1-\frac{c_{t_it_k}}{N})^{1-A_{ik}}\psi_{t_k}^{k\to i}\tag{3.1.5}\]这样的迭代方式会对任意一对节点间的信息进行更新,时间复杂度很高\(O(N^2)\)。然而考虑\(N\to \infty\),\(i\)给非邻居节点\(j\)发的信息都是一样的,假设\((i,j)\notin E\),\(\partial i\)表示与\(i\)连边的邻居:
\[\begin{aligned}\psi_{t_i}^{i\to j}&=\frac{1}{Z^{i\to j}}n_{t_i}[\prod_{k\notin \partial i \setminus j}\sum_{t_k}c_{t_it_k}^{A_{ik}}(1-\frac{c_{t_it_k}}{N})^{1-A_{ik}}\psi_{t_k}^{k\to i}][\prod_{k\in \partial i}\sum_{t_k}c_{t_it_k}^{A_{ik}}(1-\frac{c_{t_it_k}}{N})^{1-A_{ik}}\psi_{t_k}^{k\to i}]\\&=\frac{1}{Z^{i\to j}}n_{t_i}[\prod_{k\notin \partial i \setminus j}\sum_{t_k}(1-\frac{c_{t_it_k}}{N})\psi_{t_k}^{k\to i}][\prod_{k\in \partial i}\sum_{t_k}c_{t_it_k}^{A_{ik}}\psi_{t_k}^{k\to i}]\\&=\frac{1}{Z^{i\to j}}n_{t_i}[\prod_{k\notin \partial i \setminus j}1-\frac{1}{N}\sum_{t_k}c_{t_it_k}\psi_{t_k}^{k\to i}][\prod_{k\in \partial i}\sum_{t_k}c_{t_it_k}\psi_{t_k}^{k\to i}]\\&\overset{N\to \infty}{=}\frac{1}{Z^{i\to j}}n_{t_i}[\prod_{k\in \partial i}\sum_{t_k}c_{t_it_k}^{A_{ik}}\psi_{t_k}^{k\to i}]\\&=\psi_{t_i}^i\end{aligned}\]其中第二行到第三行用到\(\sum_{t_k}\psi_{t_k}^{k\to i}=1\)。第三行到第四行中间项化为1:\(N\to \infty\)时,\(\sum_{t_k}c_{t_it_k}\psi_{t_k}^{k\to i}\)相比于\(N\)是个常数,设为\(C\)。连乘的项数近似为\(N\)。所以中间项近似为\(lim_{N\to \infty}(1-\frac{C}{N})^N=1\)。
\(i\)发给邻居节点\(j\)的信息为:
\[\begin{aligned}\psi_{t_i}^{i\to j}&=\frac{1}{Z^{i\to j}}n_{t_i}[\prod_{k\notin \partial i }\sum_{t_k}c_{t_it_k}^{A_{ik}}(1-\frac{c_{t_it_k}}{N})^{1-A_{ik}}\psi_{t_k}^{k\to i}][\prod_{k\in \partial i\setminus j}\sum_{t_k}c_{t_it_k}^{A_{ik}}(1-\frac{c_{t_it_k}}{N})^{1-A_{ik}}\psi_{t_k}^{k\to i}]\\&=\frac{1}{Z^{i\to j}}n_{t_i}[\prod_{k\notin \partial i }1-\frac{1}{N}\sum_{t_k}c_{t_it_k}\psi_{t_k}^{k\to i}][\prod_{k\in \partial i\setminus j}\sum_{t_k}c_{t_it_k}\psi_{t_k}^{k\to i}]\\&=\frac{1}{Z^{i\to j}}n_{t_i}[1-\frac{1}{N}\sum_{k\notin \partial i}\sum_{t_k}c_{t_kt_i}\psi_{t_k}^{k\to i}+O(\frac{1}{N^2})][\prod_{k\in \partial i\setminus j}\sum_{t_k}c_{t_it_k}\psi_{t_k}^{k\to i}]\\&\approx \frac{1}{Z^{i\to j}}n_{t_i}e^{-h_{t_i}}[\prod_{k\in \partial i\setminus j}\sum_{t_k}c_{t_it_k}\psi_{t_k}^{k\to i}],\ h_{t_i}=\frac{1}{N}\sum_{k\notin \partial i}\sum_{t_k}c_{t_kt_i}\psi_{t_k}^{k\to i}\end{aligned}\tag{3.1.6}\]最后一行,利用了\(e^{-x}\approx1-x\)。然而论文\(h_{t_i}\)为:
\[h_{t_i}=\frac{1}{N}\sum_{k}\sum_{t_k}c_{t_kt_i}\psi_{t_k}^{k}\]第二处不同最后一项\((i,k)\notin E\)时,\(\psi_{t_k}^{k\to i}=\psi_{t_k}^{k}\),可以理解。第一处不同可能是论文错误TODO。
这样,初始化所有信息,经过(3.1.6)不断迭代至收敛,计算边际概率为:
\[v_i(t_i)=\psi_{t_i}^i=\frac{1}{Z^{i}}n_{t_i}e^{-h_{t_i}}\prod_{j\in \partial i}\sum_{t_j}c_{t_it_j}\psi_{t_j}^{j\to i}\tag{3.1.7}\]Phase Transition
考虑一个特殊的情况:一个由SBM模型生成的无向图,每一个组\(a\)的平均度\(c\)都相等:
\[\sum_{d=1}^qc_{ad}n_d=\sum_{d=1}^qc_{bd}n_d=c\tag{4.0.1}\]注:\(c_{ad}n_d=Np_{ad}n_d=N_dp_{ad}\),可以理解为组\(a\)平均每个点连接到组\(d\)的边的数量,在对所有组\(d\)遍历求和,即为组\(a\)的平均度。满足这样条件的模型叫做:factorized block model.
Factorized fixed point
BP:(3.1.6)和(3.1.7),的一个不动点(叫做factorized fixed point)为:
\[\psi_{t_i}^{i\to j}=n_{t_i}\tag{4.1.1}\]可以将不动点(4.1.1)代入(3.1.6)验证这个不动点:
\[\begin{aligned}\psi_{t_i}^{i\to j}&=\frac{1}{Z^{i\to j}}n_{t_i}e^{-h_{t_i}}[\prod_{k\in \partial i\setminus j}\sum_{t_k}c_{t_it_k}\psi_{t_k}^{k\to i}]\\&= \frac{1}{Z^{i\to j}}n_{t_i}e^{-\frac{1}{N}\sum_{k\notin \partial i}\sum_{t_k}c_{t_kt_i}\psi_{t_k}^{k\to i}}[\prod_{k\in \partial i\setminus j}\sum_{t_k}c_{t_it_k}n_{t_k}]\\&=\frac{1}{Z^{i\to j}}n_{t_i}e^{-\frac{1}{N}\sum_{k\notin \partial i}\sum_{t_k}c_{t_kt_i}n_{t_k}}[\prod_{k\in \partial i\setminus j}\sum_{t_k}c_{t_it_k}n_{t_k}]\\&=\frac{1}{Z^{i\to j}}n_{t_i}e^{-\frac{1}{N}\sum_{k\notin \partial i}c}[\prod_{k\in \partial i\setminus j}c]\\&=\frac{n_{t_i}e^{-\frac{1}{N}\sum_{k\notin \partial i}c}\prod_{k\in \partial i\setminus j}c}{\sum_{n_{t_i}}n_{t_i}e^{-\frac{1}{N}\sum_{k\notin \partial i}c}\prod_{k\in \partial i\setminus j}c}\\&=n_{t_i}\end{aligned}\]将这个factorized fixed point代入(3.1.7),得到边际分布:
\[\begin{aligned}\psi_{t_i}^i&=\frac{1}{Z^{i}}n_{t_i}e^{-h_{t_i}}\prod_{j\in \partial i}\sum_{t_j}c_{t_it_j}\psi_{t_j}^{j\to i}\\&=\frac{1}{Z^{i}}n_{t_i}e^{-h_{t_i}}\prod_{j\in \partial i}\sum_{t_j}c_{t_it_j}n_{t_j}\\&=\frac{1}{Z^{i}}n_{t_i}e^{-h_{t_i}}\prod_{j\in \partial i}c\\&=n_{t_i}\end{aligned}\]可以看出,每一个节点的分布与该节点没有关系,若根据这个分布inferring the group assignment,则每一个节点的group都是最大的group。计算这样的group assignment的overlap为0:
\[Q(\left\lbrace t_i\right\rbrace ,\left\lbrace q_i\right\rbrace )=max_\pi\frac{\frac{1}{N}\sum_i\delta_{t_i, \pi(q_i)}-max_an_a}{1-max_an_a}=\frac{max_aN_a/N-max_an_a}{1-max_an_a}=0\]这样的分布没有提供任何真实的group assignment的信息。如果BP算法收敛到这个不动点,则不可能还原真实的group assignment。以此,论文分析了在community detection中detectability-undetectability的相变点。
Stability of factorized fixed point
考虑随机扰动BP算法中的边际分布对BP算法的factorized fixed point的影响。在一个稀疏网络的情况下,网络是局部树状的。考虑一个\(d\)层的树,对其叶子节点上的factorized fixed point的边际分布进行扰动:
\[\psi_t^k=n_t + \epsilon_t^k\tag{4.2.1}\]然后研究在所有\(c^d\)个叶子节点上的扰动对根节点的影响。假设每个叶子节点的影响相互独立,考虑叶子节点到根节点的一条路径\(d,d-1,d-2,...,i+1,i,...,1,0\)。定义一个迁移矩阵:
\[\begin{aligned}T_i^{ab}&=\frac{\partial\psi_a^i}{\partial\psi_b^{i+1}}|_{\psi_t=n_t}\\&=(\frac{\psi_a^ic_{ab}}{\sum_rc_{ar}\psi_r^{i+1}}-\psi_a^i\sum_s\frac{\psi_s^ic_{sb}}{\sum_rc_{ar}\psi_r^{i+1}})|_{\psi_t=n_t}\end{aligned}\tag{4.2.2}\]此公式推导还未知TODO。
由公式(4.2.2)继续推导,利用(4.0.1)的平均度为\(c\)的假设:
\[\begin{aligned}T_i^{ab}&=\frac{n_ac_{ab}}{\sum_rc_{ar}n_r}-n_a\sum_s\frac{n_sc_{sb}}{\sum_rc_{ar}n_r}\\&=\frac{n_ac_{ab}}{c}-n_a\frac{c}{c}\\&=n_a(\frac{c_{ab}}{c}-1)\end{aligned}\tag{4.2.3}\]得到迁移矩阵之后,我们可以得到相邻两个节点之间的边际概率的关系(一阶的泰勒公式):
\[\psi_a^i=\frac{\partial\psi_a^i}{\partial\psi_b^{i+1}}\psi_b^{i+1}+{\psi_a^i}_{\psi_b^{i+1}=0}\]将公式(4.2.1)代入,可以得到相邻两个节点之间边际概率的扰动之间的关系:
\[\begin{aligned}\epsilon_a^i&=\frac{\partial\psi_a^i}{\partial\psi_b^{i+1}}\epsilon_b^{i+1}\\&=T_i^{ab}\epsilon_b^{i+1}\end{aligned}\]\(T_i^{ab}\)与\(i\)无关,其矩阵形式记作\(T\)。每一个节点的边际分布\(\epsilon^i\)是一个向量(\(q\)维)表示,上式可用矩阵表示为:
\[\epsilon^i=T\epsilon^{i+1}\]最终可以得到这条路径的叶子节点与根节点的扰动之间的关系:
\[\epsilon^0=T^d\epsilon^d\tag{4.2.4}\]当\(d\to \infty\)时,\(T^d\)由\(T\)的绝对值最大的特征值\(\lambda\)主导即:
\[\epsilon^0\approx\lambda^d\epsilon^d\]这里举个例子解释下:若二维矩阵\(T\)有两个特征值:
\[Tv_1=\lambda_1,Tv_2=\lambda_2\]这两个特征向量组成二维平面的基,则任意向量\(x\)可分解为:
\[x=u_1v_1+u_2v_2\]则:
\[Tx=u_1\lambda_1v_1+u_2\lambda_2v_2\\ T^dx=u_1\lambda_1^dv_1+u_2\lambda_2^dv_2\]易见,\(d\to \infty\)时,\(T^dx\)由\(T\)的两个特征值中绝对值较大的一个主导。
假设\(c^d\)个叶子节点上的扰动\((\epsilon^{dk}, k \in 1,2,...,c^d)\)均值为0: \(\left\langle\epsilon^{dk}\right \rangle=0\)。则根上扰动的均值也为0:
\[\left \langle \epsilon^0 \right \rangle=\left\langle \sum_k^{c^d}\lambda^d\epsilon^{dk}\right\rangle=0\]而根上扰动的方差为:
\[\begin{aligned}\left \langle (\epsilon^0)^2 \right \rangle&=\left\langle (\sum_k^{c^d}\lambda^d\epsilon^{dk})^2\right\rangle\\&=\lambda^{2d}\left\langle (\sum_k^{c^d}\epsilon^{dk})^2 \right\rangle\\&=\lambda^{2d}\left\langle \sum_k^{c^d}(\epsilon^{dk})^2 + 2\sum_{k_1,k_2}\epsilon^{dk_1}\epsilon^{dk_2} \right\rangle\\&=\lambda^{2d}\left\langle \sum_k^{c^d}(\epsilon^{dk})^2\right\rangle\\&\approx\lambda^{2d}c^d\left\langle (\epsilon^{dk})^2\right\rangle,k\in1,2,3,...,c^d\end{aligned}\tag{4.2.5}\]假设每一个叶子节点扰动\(\epsilon^{dk}\)是一个均值为0,方差为1的高斯分布,则上式倒数第二个等式可以理解为两个均值为0的高斯分布的乘积仍未均值为0的高斯分布。上式最后一个等式为在\(d\to \infty\)时的近似。
高斯分布的公式为:
\[f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]设两个高斯分布为\(N\sim (\mu_1, \sigma_1)\),\(N\sim (\mu_2, \sigma_2)\)。则两个分布乘积的pdf为:
\[g(x)=\frac{1}{2\pi\sigma_1\sigma_2}e^{-\frac{(x-\mu_1)^2}{2\sigma_1^2}-\frac{(x-\mu_2)^2}{2\sigma_2^2}}\]考虑高斯分布的指数部分\(-\frac{(x-\mu)^2}{2\sigma^2}\),其一阶导数的零点为高斯分布的均值。对\(g(x)\)的指数部分求一阶导,计算均值得到\(g(x)\)的均值为:
\[\begin{aligned}\frac{(x-\mu_1)^2}{2\sigma_1^2}+\frac{(x-\mu_2)^2}{2\sigma_2^2}&=0\\x&=\frac{\frac{\mu_1}{2\sigma_1^2}+\frac{\mu_2}{2\sigma_2^2}}{\frac{1}{2\sigma_1^2}+\frac{1}{2\sigma_2^2}}\\x&=\frac{\mu_1\sigma_2^2+\mu_2\sigma_1^2}{\sigma_1^2+\sigma_2^2}\end{aligned}\]所以,如果两个高斯分布均值都为0,则它们的乘积的均值也为0。
由公式(4.2.5)可知,当\(\lambda^2c<1\)时,叶子节点上的扰动方差对根部节点的影响会逐渐消散,不动点稳定。而相反\(\lambda^2c>1\)时,这个影响会逐步放大,对不动点稍微的扰动就会使结果脱离不动点,不动点不稳定。所以不动点稳定的临界条件为:
\[c\lambda^2=1\tag{4.2.6}\]考虑模型所有\(q\)个组大小相等,\(c_{aa}=c_{in}\),\(c_{ab}=c_{out}\)。根据公式(4.2.3),可以验证,矩阵\(T\)有两个特征值:\(\lambda_1=0\),对应特征向量\((1,1,1,...,1)\);\(\lambda_2=(c_{in}-c_{out})/qc\),对应特征向量形式为\((0,0,1,-1,0,0,...,0)\)。
在本节的条件下,矩阵\(T\)为:
\[T=\begin{bmatrix} n_1(\frac{c_{11}}{c}-1)& n_1(\frac{c_{12}}{c}-1) & ... & n_1(\frac{c_{1q}}{c}-1)\\ n_2(\frac{c_{21}}{c}-1)& n_2(\frac{c_{22}}{c}-1) & ... & n_2(\frac{c_{2q}}{c}-1)\\ ... & ... & ... & ...\\ n_q(\frac{c_{q1}}{c}-1)& n_q(\frac{c_{q2}}{c}-1) & ... & n_q(\frac{c_{qq}}{c}-1) \end{bmatrix}\]由公式\(\frac{c_{in}+(q-1)c_{out}}{q}=c\)有:
\[T\overrightarrow{1}=\begin{bmatrix}n_1(\frac{c_{in}+(q-1)c_{out}}{c}-q)\\.\\.\\.\end{bmatrix}=\overrightarrow{0}=0\overrightarrow{1}\]另由\(n_1=n_2=...=\frac{1}{q}\):
\[T\begin{bmatrix}1\\-1\\0\\.\\.\\.\\0\end{bmatrix}=\begin{bmatrix}n_1\frac{c_{in}-c_{out}}{c}\\n_2\frac{c_{out}-c_{in}}{c}\\0\\.\\.\\.\\0\end{bmatrix}=\frac{c_{in}-c_{out}}{qc}\begin{bmatrix}1\\-1\\0\\.\\.\\.\\0\end{bmatrix}\]可以看出\(\lambda_2=(c_{in}-c_{out})/qc\)的特征值为q-1阶。
将\(\lambda_2\)代入(4.2.6)有:
\[|c_{in}-c_{out}|=q\sqrt{c}\tag{4.2.7}\]当\(\|c_{in}-c_{out}\|>q\sqrt{c}\)时,factorized fixed point是不稳定的,社团是可检测的。这直观看也很合理,当组内的连边比组外连边更多时,网络的社团结构更清晰,更容易检测。